
Home » Measuring ROI
Category Archives: Measuring ROI
Aon channels Britney Spears in Lyra report

An open (and also sent, received, read and unobjected to) letter to Aon’s chief actuary, Ron Ozminkowski.
Dear Mr. Ozminkowski,
It seems that there are always some rookie mistakes in your analyses. Either that, or you are simply “showing savings” because your clients are oxymoronically paying you as “independent actuaries” specifically to show savings. I will assume that your mistakes are just rookie mistakes, rather than deliberate misstatements. Yet as I recall, you never fixed your Accolade analysis after it was pointed out that your own assumptions, when correctly analyzed by someone whose IQ possesses that critical third digit, inexorably led to the opposite conclusion: Accolade loses money.
Perhaps that bug is a feature for your clients, and indeed your job description is to “show savings.” Mine is the opposite: to demonstrate integrity.
If I am wrong and you are genuinely trying to do the right thing, I would be happy to fly out there and teach you people how to do arithmetic, because, in the immortal words of the great philosopher Britney Speers, oops, you did it again. This time for Lyra. With all the money they paid you, it seems like they should be able to expect correct analysis. They might be very disappointed in you.
On the off-chance that you’d like to see what a real study design looks like in mental health, Acacia Clinics would be a good one to review. Here is the Validation Institute report and here is the science underpinning it.
If you are quite certain your arithmetic is correct despite all indications to the contrary, I would invite you to bet. I say that Acacia Clinics study design and analysis is correct and your study design and analysis is wrong. You say the opposite. Here are the rules for the bet. If you won’t bet, you are of course conceding that Acacia’s analysis is correct and your analysis, to use a technical biostatistical term, sucks.
I am already finding five rookie mistakes, and I’ve only read the first five pages.

First take a looksee at this screenshot below. I was having a lot of trouble figuring out how the red dots showing something you’ve dubbed the “efficiency ratio” (a term which apparently has no meaning in health services research, as far as Google is concerned, while ChatGPT thinks it means something else altogether, but what do they know?) were related to the differences in the size of the bars. Then I realized you accidentally started the y-axis at $4000 instead of $0. A rookie mistake, which inadvertently makes the alleged savings look about 3 times higher than they are.
Meaning your so-called “efficiency ratio” is the value in the blue bar as a percentage of the gray bar, not the height of the blue bar as a percentage of the gray bar. Call me a traditionalist, but in my humble opinion those two ratios should be the same. (Note: apologies for the blurry screenshot. That’s how it’s reproducing.)

I did notice that later on, pretty much the same data in Figure 1 was reproduced as Figure 2, but this time you started the y-axis at $1000. So you’re definitely getting warmer!

Happy New Years!
Second, you may want to check your calendar, because it is now 2024. Your analysis ends at 2021. You’ve had almost two years and five full months plus a Leap Day to update it and yet, you cut it off in 2021. A cynic might conclude that you picked that end date because the alleged benefit you are claiming regresses further to the mean in 2022 and 2023.
Looks like you threw up in front of Dean Wormer
Third, speaking of regressing to the mean, the reason a cynic could infer that conclusion is, your so-called “efficiency ratio” already was regressing to the mean. Let’s assume, for now, the unassumable: that your “matched controls” are a legitimate study design. (If it were, the FDA would allow it.) Between 2018 and 2021, according to your own numbers on that chart, participant costs rose 31% while non-participant cost rose 22%. And yet somehow that statistic appears nowhere in your report, once again a rookie mistake.

Are you having connectivity issues?
Fourth, there are two types of outcomes researchers in our industry. Those who think “matched controls” are a valid study design for this kind of analysis, and those who have a connection to the internet. If you can’t afford my seminal book, try this article on the Validation Institute website which proves – using fifth-grade arithmetic – why that methodology doesn’t work. Period.
Perhaps the giveaway why “matched controls” don’t work in this case might be that the savings started on the first day of the baseline year. An employee has one phone call (yes, that was the cutoff point to get into the study group, though some people had many more) with one of Lyra’s “220,000 high-quality providers” and their medical spending drops precipitously. I’d also love to know what Lyra’s Secret Sauce is, that lets them retain 220,000 providers, all of whom are “high-quality.”
The following things change immediately as a result of that call, even though they are not part of the conversation and require a real doctor or in the case of ER visits, a great deal of luck:
- Non-mental health emergency visits plunge by 30%
- Generic drug scripts plunge by 30%
- By 2021, even expensive specialty meds fall by more than 20%
You might want to retain a smart person to explain the difference between correlation and causation. Alternatively, perhaps you are concerned that this meteor almost hit the visitors center?

A mystery wrapped inside a riddle wrapped inside a seven-figure consulting fee
Fifth, consider that Aon has data for:
- medical claims
- diagnoses
- professional mental health spending
- inpatient mental health spending
- outpatient mental health spending
- spending on non-mental health
- ED and inpatient visits
And consider that:
- They did this study for Lyra
- The study is called “Lyra Cost Efficiency [sic*] Results”
- The “Workforce Mental Health Program information was provided by Lyra Health”
Yet somehow – despite having the aforementioned two years, five months and a leap day to prepare this study – they claim to have absolutely no idea how much Lyra’s services cost:
![]()
We suspect it is a lot, perhaps enough that mental health professional fees with Lyra for participants exceed mental health spending by non-participants. Because in addition to having to pay their “evidence-based therapists” (Lyra’s term), sales, marketing, overhead and profit, Lyra needs to pay off the benefits consultants too, to “partner with” them:

Finally, where’s the guarantee of credibility? Does Aon not stand behind its work? I guess that’s a wise move on your part, because if you did, I’d be rich. By contrast, Acacia Clinics was validated by the Validation Institute (VI). They do stand behind their work, so the VI’s findings on Acacia Clinics’ outcomes are backed by a $100,000 Credility Guarantee. That, of course, is in addition to my own guarantee.
Did Mr. Ozminkowski just damage Lyra’s reputation…and Aon’s own?
The irony here is that Lyra is considered (or was considered, until this report) a perfectly legit vendor that is providing a valuable service of connecting employees to mental health professionals that match their needs. That is especially useful these days, when mental health benefits are very skinny and mental health providers are hard to come by. The “ROI” is employee appreciation, and possibly higher productivity. Not magical reductions in medical spending completely unrelated to the issues they are calling about.
Paying off consultants (who coincidentally also send them business) to pretend otherwise could damage that reputation. A rookie mistake on their part.

Further, there are some really smart, really honest consultants at Aon. But just like one dirty McDonalds would sully all of them, organization as a whole suffers when one consultant goes rogue.
*It’s either “efficiency,” meaning the cost vs. the benefit, or “cost-effectiveness.” “Cost efficiency” is redundant. They really shouldn’t need me to tell them that – or, for that matter, anything else in their report.
Share this:

Peterson Center Kills the Diabetes Industry Dead

Last week the Peterson Health Technology Institute (PHTI, part of the Peterson Center on Healthcare) published the seminal report on the diabetes digital health industry, concluding that (with the clear exception of Virta, which we have also strongly endorsed) the minor health improvements claimed by Livongo, Omada and others nowhere near offset the substantial cost of these programs. To which we reply:

We, on the other hand, have known this since 2019. PHTI’s excuse, such as it is, is that it was formed in 2023. We’ll let it go this time…
The Likely Impact of the Findings
The report shows that digital health vendors (once again, with the exception of Virta, which emerged as the clear – and only – winner from this smackdown) are “not worth the cost.” We would strongly recommend reading it, or at least the summary in STATNews. It is quite comprehensive and the conclusion is well-supported by the evidence.
In the short run, the effect of this report should be Mercer renouncing its “strategic alliance” with Livongo (“revolutionizing the way we treat diabetes”) and returning the consulting fees it earned for recommending them to their paying clients. (Haha, good one, Al.)
This was a rookie mistake by Mercer in the first place. Not forming the “alliance,” but rather announcing it. The whole point of benefits consultants making side deals with vendors is to do it on the QT so clients don’t notice. Hence, I’m not saying Mercer should actually renounce Livongo and harm their business model. Just that they should pretend to.
In the long run, this report should signal the end of the digital diabetes industry, meaning Livongo, Omada, Vida and a couple I’ve never even heard of. The bottom line: private-sector employers using digital solutions for diabetes may be violating ERISA’s requirement that health programs benefit employees by being “properly administered.”
The Empire Better Not Fight Back
Inevitably, the well-funded diabetes industry will fight back against PHTI’s report and “challenge the data.” They’d be right in one respect: the data does need to be “challenged.” However, it’s for the opposite reason: PHTI went far too easy on these perps.
Here is what I would have added to the report, had they retained my services. (And I’d be less than honest if I didn’t admit I had hinted they should, but I think by then their budget was fully committed.) These points will inevitably come to light in the event of a “challenge.”
Second, matched controls are invalid because you can’t match state of mind. Ron Goetzel, the integrity-challenged leader of what Tom Emerick used to call the “Wellness Ignorati,” demonstrated that brilliantly, naturally by mistake. Take a looksee at what happens when you match would-be participants to non-participants – but without giving the former a program to participate in. The Incidental Economist piled on. And then the Wellness Ignorati tried to erase history, recognizing they had accidentally invalidated their entire business model. Diabetes is no different. There’s a reason the FDA doesn’t count studies that compare participants to non-participants, it turns out. PHTI accepted them as a control.

Third, along with sample bias there is investigator bias. Livongo’s main study was done by — get ready — Livongo. Along with some friends-and-relations from Eli Lilly and their consultants. PHTI assumed investigators were on the level. I’d direct them to Katherine Baicker’s two studies on the wellness industry. The first – whose “3.27-to-1 ROI” pretty much greenlit the wellness industry – was a meta-analysis of studies that were done – get ready – by the wellness industry. It has been cited 1545 times. The second, featuring Prof. Baicker’s own independently funded primary research, found exactly the opposite. It has been cited 16 times.
Don’t get us started on Livongo



Oops, make that a million and one.
Drawing undue attention to unwanted publicity has henceforth been termed The Streisand Effect. Right now this PHTI report is mostly of interest to the cognoscenti. Most of its customers won’t notice.
Why? Because what we say about wellness is likely also true here: “There are two kinds of people in the world. People who think diabetes digital health works, and people who have a connection to the internet.”
Share this:


WTF! Introducing the wellness industry’s Wishful Thinking Factor

Finally! A valid way to measure wellness outcomes that requires only a calculator, a triple-digit IQ, and complete suspension of disbelief! Introducing the Wishful Thinking Factor, or WTF. Those of you accustomed to reviewing wellness vendor outcomes may think those initials stand for something else…and we will indeed use those initials in their more common context at the end of this posting.
By contrast, this WTF is defined as:
Dollars claimed as savings/percent improvement in risk factors.
The elegance of the WTF is exceeded only by its widespread acceptance. WTF is already the wellness industry’s preferred analysis, so I am merely confirming that we agree. The only difference between my WTF calculation and theirs is they don’t actually put the numerator and denominator on the same page.
Meaning, they don’t actually announce: “Here’s our huge savings generated by our trivial risk reduction…wait…this is impossible…WTF???”
That’s because then it would be perfectly obvious that they are fabricating the savings. Instead they put “dollars saved” on one page and the improvement in risk factors on another page, way far away — and hope nobody compares them. (Interactive Health is the most stable genius example of that, as we’ll see below.)
What is the real causal relationship between risk reduction and savings?
A distressingly relevant joke circulated among us rip-roaringly hilarious faculty back when I taught in the Harvard economics department. A chemist, physicist and economist are stranded on a desert island with only a can of beans. To open it, the physicist suggests dropping it off a cliff, so that it will open upon impact. The chemist points out that would splatter the contents, and suggests instead that they put the can in a fire, and once the can gets hot enough, it will melt. The physicist points out that the beans would all burn up in the fire. At an impasse, they turn to the economist and ask what he would do.
The economist replies: “Assume a can opener.”
In keeping with that spirit, we will make six (count ’em, 6) equally generous assumptions for determining the true WTF:
- Every wellness-sensitive medical admission or ER visit is a direct function of the risk that the wellness vendor measures in a population. In other words, social determinants of health and genetics have nothing to do with the likelihood of a heart attack or diabetes event
- Even the dumbest wellness vendors know how to measure risk (following their five days of training in medicine)
- Employees never cheat to improve their biometric scores and never lie on their risk assessments
- Dropouts and non-participants would improve in risk at the same rate as participants do, so the fact that they don’t participate doesn’t change the overall risk reduction in the population
- No lag time between risk reduction and event avoidance
- No false positives, no added lab tests, drugs, doctor visits or anything else that might possibly increase utilization and cost of outpatient care in order to reduce inpatient utilization — which of course is the opposite of what the wellness trade association readily admits to:

Using those generous assumptions, measured wellness-sensitive medical admissions (WMSAs), and the total cost of those events, would decline at the same rate as measured risk declines. According to the Health Enhancement Research Organization, WSMAs comprise no more than $100 PEPY in a commercially insured population. So every 1% decline in risk yields a spending decline of $1.
Relaxing the assumptions above would likely reveal that this WTF is also overstated, but it has the advantage of consensus among the 60+ experts who contributed to the HERO outcomes guidelines measurement tool, so we’ll call this the Gold Standard, to which other WTFs are compared.
Now let’s make a little list of the WTFs compiled by the industry’s very stable geniuses, in their great and unmatched wisdom. Naturally, in that category, the first to come to mind are Interactive Health and Ron Goetzel.
Let’s start with Interactive Health. Excluding dropouts and non-participants, they claimed a 5.3% risk reduction (20.3% reduced risk while 15% increased them). So they saved a maximum, assuming the six assumptions above, $5.30 PEPY:
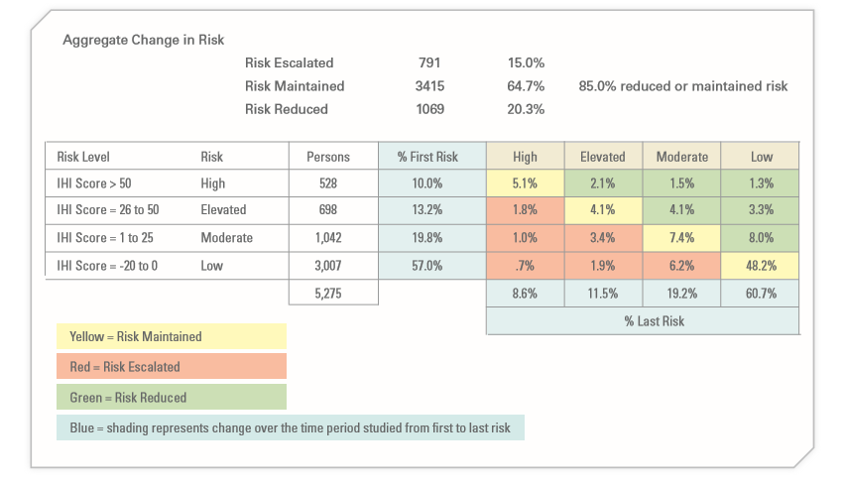
The claimed savings was:

Averaging those claims yields $804, for a WTF of 151.
As a side note, allocating that $804 in savings across the 5.3% who actually did see a decline in risk factors yields over $15,000 per risk factor reduced. No mean feat when you figure that the average person only incurs about $6000 in employer spending. That was enough to get them in the Wall Street Journal
A second example (and there are many more) is the Koop Award given to Health Fitness Corporation for lying about saving the lives of cancer victims who never had cancer. The coverup of that fabrication was the lead story about Nebraska, along with whether Ron Goetzel had committed an actual crime, as opposed to simply snookering the rather gullible state, whose reaction when they found out is best described as Human Resources-meets-Stockholm Syndrome.
Mr. Goetzel defended his actions by saying that lying about saving the lives of cancer victims was overlooked by the awards committee, and what really earned Nebraska the award was saving $4.2 million by reducing 186 risk factors. Let’s calculate the WTF from that.

the absolute reduction in risk was 0.17 (1.72 to 1.55) on a scale of 7, or roughly 2.4%. That represents about 180 people out of 5199 reducing a risk factor. (Of course, the remaining 15,000 of the 20,000+ state employees dropped out and/or wanted nothing to do with this program, but that’s a different story. So much winning!)
And yet somehow, despite only 180 people claiming to reduce a risk factor, the program saved $4.2-million, or $807 apiece for the total 5199 people. That yields a WTF of 336.
Speaking of Koop Awards, The Koop Award Committee is known for its embrace of WTF arithmetic, and it’s that time of year again during which they put their very good brains on full display. For instance, they once gave an award to Pfizer for saving $9 million, or roughly $300 per employee. How did Pfizer do that? With a 2% risk factor decline. Pfizer’s WTF worked out to about 150.
As a sidebar, Pfizer’s award application includes our all-time favorite displays:
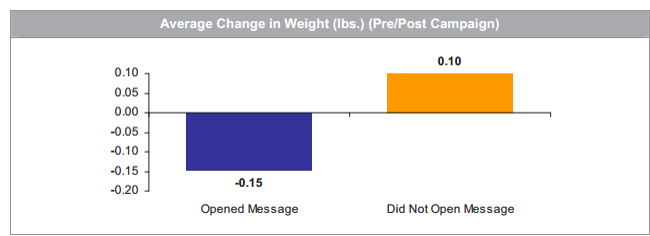
Pfizer’s wellness team sent employees emails on weight control tips. Those who opened the messages lost about 3 ounces while those who did not open the messages gained 2 ounces. That could easily be accounted for by the number of calories required to open the emails.
The 2019 Koop Award
Most recently, the very stable geniuses just gave an award to Baylor Medical School, where, in keeping with tradition, risk factors declined by a whopping 1% — at least among the 25% of the workforce willing to be screened twice (!!!) a year to earn a 20% premium reduction. Let’s take a looksee at the biometric screening results:

On average, these five categories improved 1.04%, to be exact. This is actually quite an accomplishment for the vendor, Vitality, which typically gets no improvement or a deterioration.
The claimed savings — in keeping with Koop Award tradition, buried deep on another page — were $333/year, yielding a WTF of 320.
For any readers out there with the IQs of a Koop Award Committee member, let me spell out the pattern you’re seeing: the wellness industry’s own data yields WTFs 150 to 336 times greater than the wellness industry’s own guidebook estimates.
If anyone would like to reach me to review this arithmetic, or report their own vendor’s results, contact me directly. Schedule-wise, I’m not available today (Monday) or Tuesday. However I am available later this week, specifically WTF.
Share this:


Upcoming webinar: Is is time for a wellness reboot?
Facts are the wellness industry’s kryptonite.

How do we know this?
Last month you may have seen ads from the Health Enhancement Research Organization for something called The JAMA Wellness Study: A Balanced Discussion.
Unfortunately for anyone who for whatever reason dialed into this session, that’s an hour you’ll never get back. Balancing fact and fiction in a webinar leads to curious results. For instance, here’s what would you’d learn by attending a “balanced” webinar on astronomy:
- Ptolemy: The sun revolves around the earth.
- Copernicus: The earth revolves around the sun.
- Balance: The earth revolves halfway around the sun and the sun revolves halfway around the earth.
And that’s exactly what happened here. Instead of actually presenting factual information, as in their very own candid albeit subsequently retracted foray into integrity, HERO wrote:
Hundreds of research studies published in scientific journals conclude that well designed, evidence based, comprehensive health and well-being initiatives work. We know this, yet occasionally, a new study is published that is inconsistent with the overall body of research.
The only thing more tortured than the grammar of that passage are the logic and the facts. Logically, math and science are not popularity contests. It wouldn’t matter if “hundreds of research studies” say the opposite, if indeed the opposite is wrong as a matter of arithmetic proof.
In any event, there are not “hundreds of research studies” showing “evidence-based” wellness programs work, for the simple reason that (along with the math) the “evidence basis” goes exactly the other way.
- The US Preventive Services Task Force and Choosing Wisely recommend against screening the stuffing out of employees, based on the evidence (“tests and screenings can cause problems”);
- You can’t pay people to lose weight any more than you can pay people to cure disease. Obviously if financial incentives were all it took to lose weight, Oprah Winfrey would be Size 2 by now. Quite the contrary, outcomes-based wellness that by definition requires paying people to lose weight, or fining them if they don’t, causes binge-eating and crash-dieting…and has seriously harmed employees with eating disorders;
- The last 5 winners of the wellness industry’s C. Everett Koop Award lost money–and in the most recent case of Wellsteps, harmed employees;
- The last 12 studies published have shown huge losses.
Having seen this webinar promoted, I thought it would be a good idea to enlist some card-carrying grownups to do a fact-based webinar as a counterpoint to a webinar balancing fact and fiction.
One of the original entries in my Rolodex (and that’s how far back we go) for card-carrying grownups would be the Pittsburgh Business Group on Health. PBGH is hosting a webinar on this very topic (meaning wellness) on July 9th. It will present actual facts about wellness outcomes. In that sense it will be the first webinar of its kind following the release of the JAMA study. Entitled Wellness: Is It Time for a Reboot, the registration link is here.
One fact all parties can agree on, unfortunately, is that this webinar will set you back $25. (There are a few friend-of-Al promo codes available.)

“And so, Little Miss Minnow, the wolf ate the big bad outcomes-based wellness vendor, and all the employees lived happily ever after.”
.
Share this:


Ron Goetzel Spins Gold into Straw, Part 2 (a semi-guest post by Bob Merberg)
First, congratulations to Joe Andelin, who caught just about every fallacy, alternative fact and, if there were such a thing, alternative fallacy in yesterday’s presentation. I know he did because I was on the call.
Wait, Al, didn’t you say they blocked you?
Yes, but displaying the same level of competence that they routinely bring to their day jobs, they managed to block only my video, not my audio.
Here were our predictions we got on the nose. We predicted he would say:-
- The study only covered the first year — he won’t mention that the authors also said the first year suggests nothing “is trending towards savings” in future years either;
- He said he study contradicts many of the other findings out there — except, of course, for all the other studies testing the par-vs-non-par study design against a benchmark, all of which showed results quite literally identical to the University of Illinois result, in that the wellness program accomplished zero;
- It wasn’t a good program. To hear Ron tell it (literally hear him tell it — you can listen to the tape), anytime a program fails, it’s because it wasn’t done correctly. “100 employers [have] programs with really smart ingredients…but thousands of others still don’t do wellness right,” are his exact words in print. He is refusing to name any of them, other than the old Johnson & Johnson analysis. (J&J is a wellness vendor. Investigator bias, anyone?)
The last is his go-to excuse. He said the University of Illinois program, which consisted of screenings and incentives to use the gym, was a “throwback to the 1980s.” In reality, the program was a “throwback” to every single Koop Award-winning program, all of which feature “pry, poke and prod” programs and some kind of fitness incentive. The only thing missing from this program was the broccoli.

I was wondering where to go with the rest of this posting but then into my comments box popped my old friend Bob Merberg, who is perhaps the smartest person I have ever met on the subject of wellness outcomes measurement. His comments are better than anything I could have written (assuming I had been allowed to see the slides). Here they are in their entirety:
Al, I’m not usually one to comment on other people’s blog posts, and certainly not one to promote my own content, but I attended the webinar and found the conclusions drawn by the presenters to be egregious. One of the presenters correctly pointed out that subjects in the treatment group were, “More likely to report that the employer values worker health and safety.”
But then — bizarrely — he went on to say, “In other words, … people felt more engaged, and had better morale, and had better feelings of satisfaction working for the employer by being in the treatment group. In my mind, the headline ought to be ‘Wellness Program Increases Employee Engagement and Morale’ as opposed to ’37 Things We Didn’t Find Any Difference In.‘” Another presenter termed this the key finding.
But feeling like your health and safety are valued, while important, is by no means a the same as morale, engagement, or job satisfaction. In fact, the study did not measure morale or employee engagement. It did measure job satisfaction, self-reported “bad emotional health,” and changes in happiness at work, and found that the intervention group experienced no significant improvement compared to the control group.
If we were to jump to any conclusions from this study, they might be that feeling valued are NOT linked to job satisfaction and other psychosocial metrics.
To promulgate that the “key finding” was improved morale, improved employee engagement, and improved job satisfaction, is at best a sign of failure to understand the study, and at worst a deception. Under any circumstances, it’s a disservice to the study subjects who presumably consented to participate in good faith science, to the researchers — who were meticulous in their methodology and transparency — and to those of us in the wellness industry who are more interested in understanding what works rather than distorting facts to serve our own self-interest.
But wait…there’s more.
More in my blog post: https://www.linkedin.com/pulse/employee-wellness-truth-isnt-true-bob-merberg/
Mostly for fun, a time-lapsed video of my research and writing process on this subject: https://youtu.be/hQ6HqkN-VPw
Share this:


Ron Goetzel Spins Gold into Straw, Part 1
I would invite everyone to join tomorrow (Tuesday’s) webinar by Ron Goetzel. He will be attempting to undermine the National Bureau of Economic Research’s (NBER) outstanding University of Illinois study, which showed — surprise — that conventional wellness programs don’t come close to changing behavior, let alone saving money. I would love to attend, but I, of course, am not invited to his events any more than he is invited to mine. Oh, wait a sec, I invite him to all my events and alert him to all my postings on linkedin so that he can correct any errors I’ve made. Sorry, my memory failed me there for a second.
Speaking of failed memories, he is being joined on this webinar by Jessica Grossmeier. If that name rings a bill, it’s because she claimed her company, Staywell, saved $17,000 per risk factor reduced — about $3000/pound shed — for British Petroleum, having forgotten that she herself claimed it is only possible to save $105/avoided risk factor. See “British Petroleum Wellness Program is Spewing Invalidity.”
Despite this being the Gold Standard of randomized control trials, he will be accusing the NBER of many errors. (A cynic might note that being accused of making errors in a wellness study by Ron Goetzel is like being accused of cheating on your taxes by Paul Manafort. ) He will argue that:
- The study only covered the first year — he won’t mention that the authors also said the first year suggests nothing “is trending towards savings” in future years either;
- The study contradicts — you guessed it — Kate Baicker’s infamous 3.27-to-1 ROI, without mentioning that the NBER’s principal investigator, as coincidence would have it, reports to Kate Baicker, so it’s pretty unlikely he would diss her unless the data left him no choice;
- The study contradicts all the other findings out there — except for all the other studies testing the par-vs-non-par study design against a benchmark, all of which showed results quite literally identical to the University of Illinois result, in that the wellness program accomplished zero;*
- The participants outperformed the non-participants;
- They haven’t reported on the screening yet;
- It wasn’t a good program. To hear Ron tell it (literally hear him tell it — you can listen to the tape), anytime a program fails, it’s because it wasn’t done correctly. “100 employers [have] programs with really smart ingredients…but thousands of others still don’t do wellness right,” are his exact words in print. He is refusing to name any of them, other than the old Johnson & Johnson analysis. (J&J is a wellness vendor. Investigator bias, anyone?)
What else will he argue? Tough to say. One thing for certain: he won’t mention my name — any more than Bravo did when they wrongly predicted that the EEOC rules would be replaced in January while I predicted the opposite. Instead he uses a new vernacular for my postings: “Industry chatter.”
![]()
He probably picked up this idea from Bravo, which uses the phrase “industry noise” to describe me.

Where’s Waldo-meets-Ron Goetzel: Spot the errors and you may win a big prize
So let’s make this interesting. Whoever comes up with the best smackdown of the webinar’s obvious fallacies (and omissions) automatically gets entered in the contest to win the Martha’s Vineyard vacation, with the house, car and private (well, semi-private) beach. It is otherwise open only to people who have won various Quizzify trivia contests, but being able to identify five or ten pieces of “chatter” or “noise” in this self-anointed “expert webinar” clearly counts as being health-literate. To compete, send me an email with an attachment. I’ll pick a couple of finalists and put them on linkedin. (If you don’t want your name used — and Ron does bite back, so I don’t blame you — I will post on my own.)

*The result is also quite consistent with Ron’s observation that there is basically no change in behavior leading to risk reduction. If we are splitting hairs here, Ron found a 1-2% reduction, not 0%. Of course, that took three years.
Share this:


A vendor’s guide to snookering self-insured employers
Dear Wellness, Diabetes, Clinic, Price Transparency, and Medication Therapy Management Vendors,
While most of you already know the majority of these tricks, there might be a few you haven’t deployed yet. So take good notes.
Sincerely,
Al Lewis
PS If you are an employer, just pass this along to your vendors…and watch your savings skyrocket. Or use “An Employer’s Guide to NOT being snookered” to see your savings become realistic.
Best practices for every vendor
Compare participants to non-participants. Using non-participants as a control for participants allows you to show massive savings without doing anything. This is not an overstatement. Here is a program — which naturally won an award for its brilliance from Ron Goetzel and his friends before I observed that they were a fraud according to their own data– that did just that. They separated participants from non-participants but didn’t bother to implement a program for two years—by which point the participants had already improved by 20% vs. the non-participants — without even having a program to participate in. (Note on this slide that the control and study group were set up in 2004 but the program didn’t start until 2006, when the cost separation had already reached the aforementioned 20%.)

Two other observational trials support this conclusion. Most recently, the National Bureau of Economic Research ran a controlled trial to test exactly this hypothesis. Sure enough, like the three observational trials, they found that virtually the entire outcome in wellness can be explained by that popular study design itself, rather than the intervention.
In any participation-based program, ignore dropouts. Assume that employees who drop out do so randomly, not because they are discouraged by their lack of progress or interest.
Draw a line upwards and then claim credit for the “savings” between the actual upward spending and the “trend” you drew. As Optum’s Seth Serxner stated so succinctly: “We can conclude that the choice of trend has a large impact on estimates of financial savings.”

Start with the ridiculously high utilizers, high-risk people, or people taking lots of drugs. Let the group regress to the mean, and then claim that as savings.
Never admit, like Wellsteps did, that you are familiar with regression to the mean, since most employers are not aware of it. The higher the costs/risks of the original users, the more savings you can claim. Here are two verbatim claims:
- A heavy equipment manufacturer found high use of the ER was a becoming a cost concern, so it send mailings that showed appropriate care settings to the homes of members with two or more visits to the ER in the past year. As a result, ER visits were down 59 percent those who got the mailing.
- A pharmaceutical company saw a spike in ER claims was coming from repeated use by the same people, so two mailers were sent: one to households with one ER visit in the past year; another for those with two or more visits. Following the mailings, there was a 63 percent drop in ER visits.
Pretend not to notice that low utilizers can show an increase in utilization — or especially that low-risk people can increase in risk. Focus the mark (I mean, the customer) on the high-risk people who decline in risk. Never draw graphs to scale, or your customer might notice that 2/3 of their employees are low-risk in the first place.
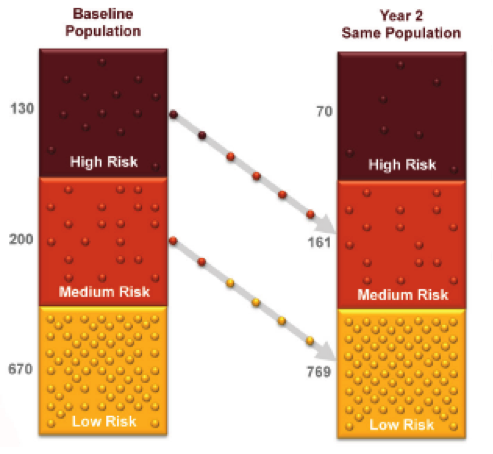
It doesn’t matter what your intervention is. Claim credit for the entire difference in trend. For instance, in this example, Community Care of North Carolina claimed credit for a huge reduction in PMPM costs for babies for their medical home program…but babies weren’t even included in the program. (Neonatal expenses didn’t decline either.)

Or do what Safeway did, launching the wellness craze: change to a high-deductible plan, and transfer a large chunk of costs to employees. Don’t even bother to institute a wellness program, but attribute all the savings (from the transferred deductible spending) to wellness anyway, so that you get invited to the White House. And after that blows up on you, demonstrate that your very stable genius investment in wellness was not a fluke by investing your company’s money in Theranos.
Special Instructions for transparency tool vendors
Assume that every employee who uses your tool is looking to save their bosses some money, rather than (for instance) to find the closest MRI…and that none of them would have used a lower-cost venue absent your tool.
If only 10% of employees use your transparency tool, and only 10% of events are shoppable, nonetheless take credit for the entire difference in trend across the board, and ignore the literature showing online price-comparison tools don’t work.
If people who haven’t met their deductible shop more than people who have, attribute the former’s lower cost to use of the tool, rather than to the fact that by definition people who don’t meet their deductible spend less than people who blow through it.
Special instructions for wellness and diabetes vendors
If you are a wellness or diabetes prevention/management vendor, never ever let employers know that every year since statistics have been kept, fewer than 1 in 1000 employees/dependents end up in the hospital with diabetes. (And another 1 in 1000 with a heart attack.) Always tell them how many employees are at risk and how many “newly discovered conditions” they have, and how they will all end up in the hospital, even though hospitalizations for heart attacks and diabetes in the employer-insured population have been declining for years.

Wellness vendors should always put the trivial percentage reduction in risk (for participants only, of course – and ignoring dropouts) on one page and the massive savings on another page. Most employers won’t bother to do the math to notice, for example, that Interactive Health claimed $50,000 in savings for every employee who reduced one risk factor, while the state of Nebraska won an award for claiming to save $20,000+ for every risk factor reduced, as did Staywell for British Petroleum.
If you didn’t reduce risk factors, present your outcomes in a format no one can make heads or tails of, like this one, from Wellsteps. If Wellsteps was able to snooker an entire committee of self-anointed outcomes experts to win an award for program excellence, surely you can snooker a few customers.

Claiming people lose weight is a big part of your outcome reporting, so make sure to do the following:
- Never count nonparticipants, and ignore dropouts.
- Don’t do any long-term follow-up to see who regained the weight (most participants)
- Give them time to binge before the initial weigh-in
Special instructions for diabetes vendors
In addition to measuring on active participants only, raise the bar for Hb A1c so that only people with high Hb A1c’s can be included. That belt-and-suspenders approach will ensure that you can’t fail to show savings, even if (as is likely the case) you don’t change anyone’s behavior other than the employees who were going to change anyway, which you might as well count.
Next — most diabetes vendors and a few wellness vendors have already figured this out — you can charge much more if you can submit claims, rather than just be an admin expense line item. You see, most employers focus much more on the 10% admin expense than they do the 90% medical expense, which they consider to be beyond their control. Your claims expense – which would draw attention to itself as an admin cost — won’t get noticed in the 90% of medical losses, sort of like the dirt from the tunnel sprinkled around the Stalag in The Great Escape.


Special instructions for medication therapy management vendors
Only mention “gaps in care” that you close, not the ones that open up. And, as noted in the chart below, always use percentages. So in this chart (provided by one of the major PBMs), they claimed that twice as many gaps were closed (37%) vs opened (18%), and yet, as is almost always the case with MTM vendors, nothing happened to the total number of gaps, which remained at exactly 820:

Tally all the employees who were on large numbers of meds and now take fewer. But don’t mention all the employers who were on fewer meds and now take more.
What to do if you’re asked why you aren’t validated by the Validation Institute
Here are the most popular answers to that question:
- No one has asked us to. (Quizzify didn’t need to be asked.)
- We hired our own outside actuarial firm to validate us, and they concluded we save a lot of money.
- Sure, we’ll get validated as soon as you sign the contract with us.
Share this:

National Bureau of Economic Research has bad news and good news for the wellness industry

Not to be confused with those immortal words often attributed to the great philosopher Yogi Berra, a big joke among economists is: “An economist is someone who upon learning how something works in practice, wonders how it will work in theory.”
That joke morphed into reality last month — though it was a controlled study testing a theory, rather than the theory itself. The “theory” would be that inactive unmotivated non-participants can be used as a control for active motivated participants. Ironically, this study design has never been proposed as legitimate, even in theory. Wellness “researchers” like it because it always show savings, even when nothing happens. For example, even when there was no program for the participants to participate in.
Obviously if this were a legitimate design, the FDA would approve it for clinical trials, saving a ton of time and money vs. having to do controlled trials.
To wit, the National Bureau of Economic Research (NBER) just published a study showing that the participants-vs-non-participants (“par-vs.-nonpar”) study design, used extensively by the very stable geniuses in the wellness industry to do their alt-research to fabricate their alt-findings, is completely invalid.
No surprise. This NBER study validates what we’ve all observed in practice — as the three examples in this article amply demonstrate. The somewhat more amusing TSW version is here.
Highlights of NBER study for the wellness industry: bad news first
First the bad news. Fasten your seat belts and be shocked, shocked to learn that the researchers could identify:
- No noticeable change in health behaviors due to the wellness program
- No noticeable change in health outcomes due to the wellness program
- Clear self-selection bias among participants opting into the wellness program
Lest anyone think we are taking this out of context, here are their exact words:
We do not find any significant effects of treatment on total medical expenditures, employee productivity, health behaviors, or self-reported health measures in the first year following random assignment. We further investigate the effect of our intervention on medical expenditures in greater detail, but fail to find significant effects on different quantiles of the spending distribution or on any major subcategory of medical expenditures (pharmaceutical, office, or hospital). We also do not find any effect of treatment on the number of visits to campus gym facilities or on the probability of participating in a popular annual community running event, two health behaviors that are relatively simple for a motivated employee to change over the course of one year.
This of course merely confirms what we observe in outcomes reports published by wellness vendors, including the two most recent proud recipients of the Deplorables Awards. Actually, in the case of Wellsteps there was indeed a noticeable change in health outcomes among program participants — they got worse.
Also, the authors — no doubt anticipating the objection from the very stable geniuses at the Health Enhancement Research Organization — specifically note that nothing in Year One’s results presage any step-function improvement in Year Two. So the specious “Wait ’til next year” argument is off the table.
You might be thinking, “Another nail in the wellness industry coffin.” True, except that there almost isn’t room for any more nails. Soon the coffin will have enough nails to create its own gravitational field.
Next, the good news
Here are the two pieces of good news for the wellness industry. One finding was:
Our 95% confidence intervals rule out 78 percent of previous estimates on medical spending and absenteeism.
That means that it is possible that 22% of previous estimates may conceivably not be completely invalid. This is not to say that 22% are valid, just that they aren’t automatically invalid. That is great news for the wellness industry, where clearing the bar for not being automatically invalid is cause for celebration. As Dave Chase says, the bar for wellness is so low a snake could jump over it.
However, the 78%-totally-invalid figure specifically invalidates Katherine Baicker, author of the so-called “Harvard Study.” Depending on whether you are a wellness vendor or an oppressed employee, she is either the Johnny Appleseed or the Typhoid Mary of wellness. Her famous 3.27-to-1 ROI was tallied entirely from par-vs.-nonpar studies, exactly the methodology that the NBER just invalidated, citing exactly the studies she cited. (The three examples in my study referenced above were also part of her meta-analysis.)
So perhaps she might now make a formal statement regarding par-vs-non-par as a study design? Either a retraction or a defense. Just something that clarifies her previous statements, which seem to be neither retractions nor defenses but rather more like excuses:
- It’s too early to tell (um, after 30 years of workplace wellness?)
- She has no interest in wellness any more
- People aren’t reading her paper right (we’re only reading the headline, the data, the findings and the conclusion, apparently)
- “There are few studies with reliable data on the costs and the benefits” (um, then how were you able to reach a conclusion with two significant digits?)
The irony is that Kate Baicker has otherwise done outstanding research. Her study on Oregon Medicaid is a classic. In Oregon at the time, Medicaid eligibility was determined by lottery amongst applicants. That meant that — quite the opposite of wellness control groups — the control group of people not picked in the lottery had equal motivation to seek insurance coverage as people who were picked. After following both groups going forward, her finding was that obtaining insurance to access basic medical care did not change outcomes. (Having insurance did bring peace of mind, though.)
And yet somehow in “Workplace Wellness Can Generate Savings,” she was quite comfortable reaching a conclusion that was completely inconsistent with her Oregon finding, not to mention the Law of Diminishing Returns: throwing additional unrequested, generally unwanted, and largely misdirected medical interventions and advice at employees who already have insurance — and recall that most insured Americans are drowning in medical care — could dramatically improve their outcomes enough to calculate not just a massive ROI, but an ROI precise to two significant digits.
What she will hopefully learn through the NBER study is something that I learned 11 years ago: when the data proves you wrong, fess up. Then people like me have to find someone else to blog about. Fortunately, in wellness, that is not a heavy lift.
The second piece of good news for the wellness industry
To quote the study:
…wellness incentives may shift costs onto unhealthy or lower-income employees if these groups are less likely to participate in wellness programs. Furthermore, wellness programs may act as a screening device by encouraging employees who benefit most from these programs to join or remain at the firm…
To be clear, this calculation does not imply that adoption of workplace wellness programs is socially beneficial. But, it does provide a profit-maximizing rationale for firms to adopt wellness programs, even in the absence of any direct effects on health, productivity, or medical spending. [emphasis theirs]
In other words, employers can use wellness programs to subtly discriminate against unhealthy — read, older and poorer — workers. Many of the very stable geniuses in the wellness industry will be happy to hear this. The exceptionally stable genius who will be most thrilled to hear this is Michael O’Donnell. Mr. O’Donnell is the former Prevaricator-in-Chief of the wellness industry trade publication and a current member of the Koop Award cabal. These are excerpts from one of his editorials:
First, he says prospective new hires should be subjected to an intrusive physical exam [editor’s note: notwithstanding the fact that this is totally illegal], and hired only if they are in good shape. OK, not every single prospective new hire needs to be in good shape — only those applying for “blue collar jobs or jobs that require excessive walking, standing, or even sitting.” Hence he would waive the physical exam requirement for mattress-tester, prostitute, or Koop Award Committee member, because those jobs require only excessive lying.
Second, he would fine people for not meeting “outcomes standards.” In an accompanying document, he defines those “outcomes standards.” He specifies fining people who have high BMIs, blood pressure, glucose, or cholesterol.
In other words, Mr. O’Donnell wants to charge for insurance by the pound, as that accompanying document says. Actually, by BMI, which of course is of dubious value as a measure of weight, let alone health.
Here is his actuarial formula:

Although having read his very stable arithmetic elsewhere in this same document, I’d worry about the accreditation status of any actuarial school, or for that matter any school of any kind within the 50 states, that would accept him:
Thirty-one states have no laws that prohibit employers from using smoking status as the reason for not hiring… In the remaining 29 states…smoking status cannot be used as the reason for not hiring.
I’m not waiting around for a retraction from this genius either.
Share this:

A Twofer: Interactive Health botches both its analysis and the cover-up
I usually say the reason I can’t expose all the lies in wellness is that there aren’t enough hours in a day. Unfortunately for Interactive Health, today there are. (In your face, Arizona residents!)
PS For my next and final posting in the Interactive Health trilogy, it would help if anyone could send me some of their outcomes reports. Obviously I won’t use your name or the name of your accounts. The advantage for you is if I use your stats, it’s like getting a free consult.
When we last left our antiheroes, we were counting the number of lies their consulting firm told in their report underpinning Interactive Health’s financial savings model. We found ten. That may not seem like a lot by wellness standards, but those were in just two little bullet points. The only people who tell more lies in fewer words have Twitter accounts.
After publication, we discovered a new tidbit about Zoe Consulting. Along with the adjectives “top-tier” and “nationally recognized,” which they used to describe themselves, another would be “hunh?” Yeah, I know, not technically an adjective but Zoe is not technically a company.
Yes, this “top-tier nationally recognized” outfit has disconnected both its internet and its telephone.
And don’t try to find them in person, either. The address listed for them shows this streetview. If you can’t quite see it on your smartphone, I can describe the scene: imagine Narnia-meets-Stephen King.

Interactive Health Outcomes Report
Zoe Consulting called me soon after my first expose of Interactive Health appeared in the Wall Street Journal, and offered to pay me not to write about Interactive Health’s squirrelly outcomes any more, at least on my old website. I agreed — but only on the condition that they promise to tell the truth in the future, which has proven to be an insurmountable hurdle.
By the way, good news for any perps who think they have to pay me to have their material removed. If you are honest and I make a mistake, I pay you! Or if you make a mistake and own up to it, I pay you.
This is not either situation. Indeed, we have never encountered either situation.
Here is the report in question. You’ll notice there are lots of claims about massive savings, extending to workers comp and disability too. But not a peep about risk factors. That’s why they call this a “research summary” and not a “research study”: they removed the actual research after I observed that it invalidated their financial claims. Speaking of which, here is their financial claim: after three years, costs are magically about 18% — thousands of dollars — lower than they would have been.

The “research summary” contains only one sentence about the program itself: “The findings below indicate actual costs fell below the projected costs due to the positive impact of the Interactive Health program.”
How “positive” was that “impact of the Interactive Health program”? Excluding dropouts which of course they conveniently ignore, the number of high-risk employees fell by 1.4%. Since spending on wellness-sensitive medical events is about $100/year, optimistically you’d save $1.40/year by reducing risk 1.4% — assuming the savings accrued immediately. To cover up their mistake, they removed the risk analysis.
Anticipating they would attempt this cover-up, I kept a screenshot. This screenshot is also quite useful to illustrate regression to the mean in my course on Critical Outcomes Report Analysis. (In the display below, the green represents improvement and the red represents deterioration. Obviously — meaning obviously to everyone except Interactive Health — people who are low risk can only get worse or stay the same, while people who are high-risk can only improve or stay the same. Classic regression to the mean.)
In this graphic, you can see 10% as the starting point and 8.6% as the ending point in the high-risk categories:
Instead of $1.40/year, they claimed savings of up to $3084/year — exaggerating by a factor exceeding 2000. Not 2000%. In wellness, 2000% would be rounding error. By contrast, a factor of 2000 equates to 200,000%.
200,000 is a big number. To put the number 200,000 in perspective, imagine stacking 6 Empire State Buildings on top of one other. Do that 200,000 times, and you reach the moon.
We are going to call Interactive Health liars. However, we don’t mean that as an insult, or even an objective observation (though that too). We mean that as a compliment. We have too much respect for their intelligence to believe that they could possibly be stupid enough to make a mistake of that magnitude.
However, if they would like to insist that they were this stupid (the “dumb and dumber” defense pioneered by Ron Goetzel) — and substitute what they now know to be the correct answer of $1.40 in place of the $3084 and circulate the revised result to their customers — we will publicly apologize for calling them liars. And, yes, we will pay them the honorarium noted above.
As for their botched cover-up of the initial results, perhaps that was just an unfortunate but inadvertent omission that coincidentally took place immediately after I pointed out their own risk analysis invalidated all their own claims about savings.
Postscript: Zoe Consulting’s Wisest Move
Zoe Consulting did do something right. At one point in the conversation I mentioned above, I recommended that they hire a smart person, based on the observation that a smart person would realize that the trivial risk factor reduction couldn’t possibly support the gargantuan savings claims. The CEO replied: “Al, the savings have nothing to do with the risk reduction. The two analyses are completely separate.”
If you are prone to comments like that, the wisest move is indeed to disconnect your phones and internet.
Share this:

Wellness Vendors Dream the Impossible Dream
Alice laughed: “There’s no use trying,” she said. “One can’t believe impossible things.”
“I daresay you haven’t had much practice,” said the Queen. “When I was younger, I always did it for half an hour a day. Why, sometimes I’ve believed as many as six impossible things before breakfast.”
Six impossible things before breakfast? The wellness industry would just be getting warmed up by believing six impossible things before breakfast. They believe enough impossible things all day long to support an entire restaurant chain:

Consider the article in the current issue of BenefitsPro — forwarded to me by many members of the Welligentsia — entitled: “Can the Wellness Industry Live Up to Its Promises?” BenefitsPro rounded up some of the leaders of the wellness industry alt-stupid segment. Specifically, they interviewed US Corporate Wellness, Fitbit, Staywell, and HERO. Each is a perennial candidate for the Deplorables Awards — except US Corporate Wellness, which already secured its place in the Deplorables Hall of Fame (and Why Nobody Believes the Numbers) several years ago with these three paeans to the gods of impossibility.

In case you can’t read the key statistic — the first bullet point — it says: “Wellness program participants are 230% less likely to utilize EIB (extended illness benefit) than non-participants.” Here is some news for the Einsteins at US Corporate Wellness: You can’t be 230% less likely to do anything than anybody. For instance, even you, despite your best efforts in these three examples, can’t be 230% less likely to have a triple-digit IQ than the rest of us. Here’s a rule of math for you: a number can only be reduced by 100%. Rules of math tend to be strictly enforced, even in wellness. So the good news is, even in the worst-case scenario, you’re only 100% less likely to have a triple-digit IQ than the rest of us.
And yet, if it were possible to be 230% dumber than the rest of us, you might be. For instance, US Corporate Wellness also brought us this estimate of the massive annual savings that can be obtained just by, Seinfeld-style, doing nothing:

So assume I spent about $3500/year in healthcare 12 years ago, which is probably accurate. My modifiable risk factors were zero then and they are still zero — no increase. So my healthcare spending should have fallen by $350/year for 12 years, or $4200 since then. But that would be impossible, since I could only reduce my spending by $3500. Do you see how that works now?
To his credit, US Corporate Wellness’s CEO, Brad Cooper, is quoted in this article as saying: “Unfortunately some in the industry have exaggerated the savings numbers.” You think?
I’m pretty sure this next one is impossible too. I say “pretty sure” because I’ve never been able to quite decipher it, English being right up there with math as two subjects which apparently frustrated many a wellness vendor’s fifth grade teacher:

400% of what? Is US Corporate Wellness saying that, as compared to employees with a chronic disease like hypertension, employees who take their blood pressure pills are 400% more productive? Meaning that if they controlled their blood pressure, waiters could serve 400% more tables, doctors could see 400% more patients, pilots could fly planes 400% faster? Teachers could teach 400% more kids? Customer service recordings could tell us our calls are 400% more important to them?
Or maybe wellness vendors could make 400% more impossible claims. That would explain this BenefitsPro article.
Fitbit
We have been completely unable to get Fitbit to speak, but BenefitsPro couldn’t get them to shut up. Here is Fitbit’s Amy McDonough: “Measurement of a wellness program is an important part of the planning process.” Indeed it is! It’s vitally important to plan on how to fabricate impossible outcomes to measure, when in reality your product may even lead to weight gain. Here is one thing we know is impossible: you can’t achieve a 58% reduction in healthcare expenses through behavior change — especially if (as in the 133 patients they tracked in one of their studies) behavior didn’t actually change.
You can read about that gem, and others, in our recent Fitbit series here:
- Springbuk wants employees to go to the bathroom
- Fitbit throws a bit of a fit, Part 1
- Fitbit throws a bit of a fit, Part 2
Health Enhancement Research Organization (HERO) and Staywell
I’ll consider these two outfits together because people seem to bounce back and forth between them. Jessica Grossmeier is one such person. Jessica became the Neil Armstrong of impossible wellness outcomes way back in 2013. Not just any old impossible wellness outcomes — those have been around for decades. She and Staywell pioneered the concept of claiming outcomes they already knew were impossible. While at Staywell, she and her co-conspirators told British Petroleum they had saved about $17,000 per risk factor reduced. So, yes, according to Staywell, anyone who temporarily lost a little weight saved BP $17,000 — enough to clean up about 1000 gallons of oil spilled from Deepwater Horizon.
See British Petroleum’s Wellness Program Is Spewing Invalidity for the details.
Leave aside both the obvious impossibility of this claim, and also the mathematical impossibility of this claim given that employers only actually spend about $6000/person on healthcare. Jessica’s breakthrough was to also ignore the fact that this $17,000/risk factor savings figure exceeds by 100 times what her very own article claims in savings. Not by 100 percent. By 100 times.
Fast-forward to her new role at HERO. In this article she says:
The conversation has thus shifted from a focus on ROI alone to a broader value proposition that includes both the tangible and intangible benefits of improved worker health and well-being.
Her memory may have failed her here too because HERO — in addition to admitting that wellness loses money (which explains its “shift” from the “focus on ROI alone”) — also listed the “broader value proposition” elements of their pry-poke-and-prod wellness programs. The problem is the elements of the broader value proposition of screening the stuffing out of employees aren’t “benefits.” They’re costs, and lots of them:

When she says: “The conversation has shifted from a focus on ROI alone,” she means: “We all got caught making up ROIs so we need to make up a new metric.” RAND’s Soeren Mattke predicted this new spin three years ago, observing that every time the wellness industry makes claims and they get debunked, they simply make a new set of claims, and then they get debunked, and then the whole process repeats with new claims, whack-a-mole fashion, ad infinitum. Here is his specific quote:
“The industry went in with promises of 3 to 1 and 6 to 1 based on health care savings alone – then research came out that said that’s not true. Then they said: “OK, we are cost neutral.” Now, research says maybe not even cost neutral. So now they say: “But is really about productivity, which we can’t really measure but it’s an enormous return.”
Interactive Health
While other vendors, such as Wellsteps, harm plenty of employees, Interactive Health holds the distinction of being the only wellness vendor to actually harm me. I went to a screening of theirs. In order to increase my productivity, they stretched out my calves. Indeed, I could feel my productivity soaring — until one of them went into spasm. I doubt anyone has missed this story but in case anyone has…
They also hold the distinction of being the first vendor (actually their consultant) to try to bribe me to stop pointing out how impossible their outcomes were. They were upset because I profiled them in the Wall Street Journal . The article is behind a paywall, so you probably can’t see it. Here’s the spoiler: they allegedly saved a whopping $53,000 for every risk factor reduced. In your face, Staywell!
Here is the BenefitsPro article’s quote from Interactive Health’s Jared Smith:
“There are many wellness vendors out there that claim to show ROI,” he says. “However, many of their models and methodologies are complex, based upon assumptions that do not provide sufficient quantitative evidence to substantiate their claims.”
You think?

Finally, here is a news flash for Interactive Health: sitting is not the new smoking. If anything is the “new smoking,” it’s opioid addiction, which has reached epidemic proportions in the workforce while being totally, utterly, completely, negligently, mind-blowingly, Sergeant Shultz-ily, ignored by Interactive Health and the rest of the wellness industry.
There is nothing funny about opioid addiction and the wellness industry’s failure to address it, a topic for a future blog post. The only impossibility is that it is impossible to believe that an entire industry charged with what Jessica Grossmeier calls “worker health and well-being” could have allowed this to happen. Alas, happen it did.
And, as you can see from the time-stamp on this post, except at establishments favored by the Wellness Ignorati, breakfast hasn’t even been served yet.

